
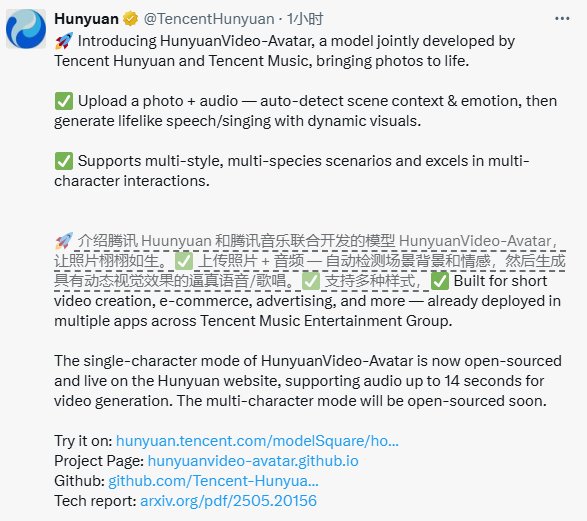
腾讯混元团队最近推出了一项令人惊叹的开源技术——HunyuanVideo-Avatar,这是一款基于语音生成数字人视频的模型。只需一张图片和一段音频,就能轻松生成自然流畅的数字人说话或唱歌视频,为短视频创作注入全新活力。
HunyuanVideo-Avatar 的核心亮点在于其强大的智能理解能力。用户上传一张人物图像与对应音频后,模型会自动解析音频中的情感和场景信息,生成高度还原的动态视频。比如,输入一张海滩上弹吉他的女性照片搭配抒情音乐,模型即可生成她边弹边唱的生动画面。
应用场景广泛
这项技术适用于短视频创作、电商广告等多个领域,大幅降低视频制作的时间与成本。无论是产品介绍还是多人互动广告,HunyuanVideo-Avatar 都能提供高效支持。
技术优势显著
HunyuanVideo-Avatar 不仅支持头部驱动,还能实现半身甚至全身场景的表现,效果远超传统工具。此外,它在主体一致性和音画同步方面表现卓越,处于行业顶尖水平。
风格多样,创意无限
该模型支持多种风格和多人场景,包括赛博朋克、2D 动漫和中国水墨画等,满足不同领域的创作需求。通过精准驱动多个角色,确保唇形、表情和动作与音频完美同步,带来更自然的互动体验。
这些功能的背后是腾讯混元团队与腾讯音乐天琴实验室的技术创新,如多模态扩散 Transformer 架构和面部感知音频适配器等,确保了视频的高质量输出。
HunyuanVideo-Avatar 的单主体功能已上线腾讯混元官网,目前支持 14 秒以内的音频生成视频,更多功能即将推出。
-
体验入口: https://hunyuan.tencent.com/modelSquare/home/play?modelId=126
-
项目主页: https://hunyuanvideo-avatar.github.io
-
Github: https://github.com/Tencent-Hunyuan/HunyuanVideo-Avatar
[hhw123pingdao]
- 请注意,下载的资源可能包含广告宣传。本站不对此提供任何担保,请用户自行甄别。
- 任何资源严禁网盘中解压缩,一经发现删除会员资格封禁IP,感谢配合。
- 压缩格式:支持 Zip、7z、Rar 等常见格式。请注意,下载后部分资源可能需要更改扩展名才能成功解压。
- 本站用户禁止分享任何违反国家法律规定的相关影像资料。
- 内容来源于网络,如若本站内容侵犯了原著者的合法权益,可联系我们进行处理,联系微信:a-000000
📝留言定制 (0)