
最近,通义实验室自然语言智能团队开源了一款超酷的多模态RAG推理框架——VRAG-RL!这款框架专为解决AI在真实业务场景中从图像、表格和设计稿等视觉内容中检索并推理关键信息的问题而设计。
一直以来,复杂视觉文档的知识检索与推理都是AI领域的硬骨头。传统RAG方法虽然在文本处理上表现不错,但在面对图像、图表等视觉信息时就显得力不从心了。现有的视觉RAG方法受限于固定的检索生成流程,难以深入挖掘视觉信息中的隐藏知识。
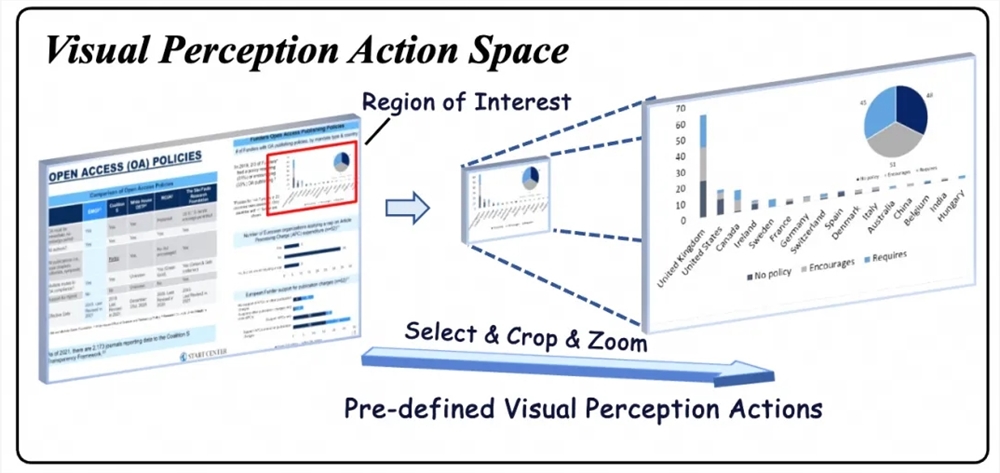
VRAG-RL通过强化学习赋能多模态智能体训练、创新视觉感知机制以及协同优化检索与推理三个维度进行了系统性升级。它引入了区域选择、裁剪、缩放等多样化的视觉感知动作,让模型能够逐步聚焦信息密集区域,精准提取关键视觉信息。
在训练过程中,VRAG-RL采用多专家采样策略,结合大规模模型的推理能力和专家模型的精确标注能力,使模型学会更高效的视觉感知策略。其细粒度奖励机制融合了检索效率、模式一致性和生成质量三方面因素,引导模型不断优化检索与推理路径。
值得一提的是,VRAG-RL还引入了GRPO算法,通过本地部署搜索引擎模拟真实应用场景,实现零成本调用搜索引擎,显著提升了训练效率和模型泛化能力。
实验结果表明,VRAG-RL在多个视觉语言基准数据集上表现出色,涵盖单跳到多跳推理、纯文本理解到图表识别等多种场景。无论是传统prompt-based方法还是基于强化学习的方法,VRAG-RL都展现出了更强的综合性能。
Github: github.com/Alibaba-NLP/VRAG
[hhw123pingdao]
温馨提示:
- 请注意,下载的资源可能包含广告宣传。本站不对此提供任何担保,请用户自行甄别。
- 任何资源严禁网盘中解压缩,一经发现删除会员资格封禁IP,感谢配合。
- 压缩格式:支持 Zip、7z、Rar 等常见格式。请注意,下载后部分资源可能需要更改扩展名才能成功解压。
- 本站用户禁止分享任何违反国家法律规定的相关影像资料。
- 内容来源于网络,如若本站内容侵犯了原著者的合法权益,可联系我们进行处理,联系微信:a-000000
📝留言定制 (0)